Abstract
지난 10년간 딥러닝은 상당한 진전을 이루었으며 광범위한 사회적 영향을 가진 문제들을 해결할 수 있는 잠재력을 보여주었음. 법과 같은 고위험 의사결정 분야에서, 전문가들은 실질적으로 ML시스템을 활용하기 위하여 해석가능성(interpretability)를 요구함. 본 연구에서는 이러한 요구 사항을 중요한 법적 인용 예측 문제(LCP, legal citation prediction)에 적용하려고 시도함. 이 과정은 변호사의 사고 과정과 유사하게 디자인 되었음. 즉, 법례와 법률 조항을 모두 참조함. 또한 초기 실험 결과를 바탕으로 법률 전문가의 피드백으로 모델의 target인 인용 예측(citation predictions)을 미세 조정한다. 또한 해석 가능성을 추가하기 위한 prototype 구조를 소개하여, 변호사가 사용하는 결정 매개변수를 준수하면서 강력한 성능을 달성함. 논문에서의 연구는 법률에 대한 최첨단 언어 처리 모델을 기반으로 하며, 실질적 사회적 영향을 가진 고위험 작업에 대한 중요한 고려 사항을 다룬다.
1. Introduction
- 고위험 문제에서는 모델이 도메인 전문가나 실무자들과 동일한 추론을 따르는지, 그렇지 않다면 왜 이러한 모델이 최종 결과에 도달하는지를 이해하는 것이 중요함.
- 따라서, 모델이 내린 결정은 해당 분야의 전문가들이 모델이 내린 결정의 정확도를 검증하고 신뢰하기 위해 인간이 그 결정을 이해할 수 있어야 한다.(require human comprehensibility)
- 법률 분야는 이러한 고위험 도메인 중 하나로, 의사 결정 과정이 상당한 사회적 영향을 미침. 따라서 논문에서는 서면에서 무엇이 가장 적절하게 인용될 법적 근거인지(=the most fitting legal citation)를 예측하는 인용예측(citation prediction)을 하는 것을 목표로 한다.
- 법률 분야에서의 인용(=citation)은 다른 분야와는 다르게 “주장이 기반으로 하는 권한의 성격”을 나타낸다. 즉, 판사들은 인용을 통한 법률 근거가 제대로 뒷받침 되지 않은 주장들을 거부할 수 있고, 인용을 통한 법적 권한 없이 주장을 펼치는 변호사들은 의견을 묵살 당할 수 있다. 이러한 이유로, 법률 분야를 다루기 위해 구축된 모든 시스템은 법정 주장의 근거를 뒷받침만할만 증거를 제시하여야 한다.
- 기존의 접근 방법은 오로지 사건의 fact으로부터 법적 인용을 예측하였음. 하지만 이는 변호사들의 사고 방식과 차이가 있음. 변호사들은 추상적인 법적 문제에서 fact를 이끌어 내 법정 주장을 펼쳤음. 다시 말해, 위반의 성격을 확인하기 위해 인용을 사용하는 것이 아닌, 법정에서의 변호사 주장에 힘을 뒷받침 하기 위해 법적 인용을 이용하였음.
- 본 연구에서는 이와 같은 문제를 해결하기 위해 Legal Citation Prediction(LCP)를 제안함.

- 이는 그림1에서 볼 수 있다 싶이 변호사의 추론을 모방하도록 설계되었음.
- 입력으로 판례(precedents)와 법조항(provisions)를 넣음.
- 해석 가능성(interpretability)를 위해 프로토타입 기반 아키텍쳐를 확장함.
- 프로토타입을 활용하면 각 법적 인용에 대해서 대표적인 예를 제시하여 줄 수 있음.
- 또한, 법적 근거들과의 유사성을 도출 할 수 있음.
- 법률 분야에 프로토타입 기반의 해석 가능성을 적용한 것은 이 논문이 처음임.
- 본 논문의 contribution은 다음과 같음.
- 법률 전문가의 피드백을 통해 개선된 LCP(Legal Citation Prediction)이라는 새로운 정의를 제시
- 프로토타입 아키텍쳐를 통해 모델을 해석 가능하게 접근. 이는 법률 분야에서 처음 시도되는 것임. 변호사의 사고 과정과 유사하게 진행할 수 있도록 해주는 loss component를 소개함.
- 이 task의 실전성에 대한 연구를 통해, 성능과 유용성을 비교하는 실험적인 증거를 제시함.
2. Related work
생략
3. Prototype-Based Legal Citation Prediction

- 우리는 그림 2와 같은 Legal Citation Prediction 작업에 대한 프로토타입 기반 아키텍처를 제안한다.
- 이는 프로토타입과의 유사성을 통해 예측을 하여, 해석 가능성(interpretability)을 높인다.
- 프로로토타입 : 각 타겟 라이블에 대한 대표적인 트레이닝 샘플(representative training samples for each target label)
- 또한, 판례와 조문 모두 고려하는 custominzed loss function을 사용하였기 떄문에, 변호사의 사고 과정과 동일한 과정으로 법적 인용 예측(legal citation prediction)을 할 수 있음.
- LCP task를 위하여, 논문에서는 1) 자동으로 찾아낸 판례에 대한 prototype과 2)수동으로 선택된 조문에 대한 prototpye의 조합을 사용함.
- baseline으로 vanilla fine-tunning을 사용함.
- 사전학습된 언어 모델에 linear classification head 추가
- 오직 case text만을 input으로 이용하여 multi-class corss-entropy loss를 통한 모든 파라미터 fine-tunning
- target label의 수 혹은 text span 제한 등의 요소로 인한 성능 trade-off 탐구
- 초기 결과로 부터 전문가 의견을 통합하여 실험 파라미터 조정
- 그런 다음, 판례 및 조문에 대한 해석가능한 latent space를 만들기 위해, 프로토타입 기반 custom loss objective를 사전학습된 base model에 추가하여 파인튜닝을 진행함.
3.1 Defining Legal Citation Prediction
- 논문에서 LCP를 법률 인용 예측을 목표로 하여 input text, 판례, 조문을 기반으로 하는 multi-label classification으로 보고 있음.
- 텍스트 구절
- possible target citation Label , where
- 목표는 적절한 target citations의 부분집합인 을 맞추는것. 는 차원 벡터로 표현됨.
- LCP의 중요한 motivation은 변호사들이 자신의 법적 주장을 뒷받침 하기 위해 legal citation을 찾을 때 수행하는 사고 과정이다. 변호사들은 판사에게 어떠한 법이 있고, 이것이 주어진 상황에서 왜 적용될 수 있는지를 설명함. 이러한 과정속에서 판례 뿐 아니라 조문 또한 참조한다.
- 기존 작업에서는 엄격하게 판례 만을 사용하거나 source text만을 사용했으나, 이 논문에서는 이 둘을 모두 사용하는 것이 인용 예측에 더 많은 context를 제공할 수 있다고 가정한다.
3.2 Training Prototypes

프로토타입 구축 과정은 알고리즘 1에서 설명하는 바와 같다.
- 먼저, 모든 훈련 세트를 잠재 공간(latent space)로 인코딩한다.
- 각 target provision 에 대하여, 그 target provision을 인용하는 내용을 담은 training samples의 부분집합 을 찾는다.
- 그리고 을 k-means를 통해 cluster시킨 후, 그 중심을 통해 prototype candidates 을 얻는다.
- 각각의 candidate 에 대하여, 코사인 유사도를 이용해 candidate candidate 와 가장 가까운 training sample인 를 찾는다.
- 만약 코사인 유사도가 기준점인 을 넘었을 경우, protype 를 의 embedding인 로 교체한다. 하지만 넘지 않았을 경우 그대로 prototype = 가 됨.

- 주어진 n개의 batch sample에 대해, 입력 임베딩 를 사용하는 input 및 feed-forward classification head 가 있을 때, loss는 식 1와 같이 표현.
- input embedding 는 CLS 토큰으로 취급되며, 유사도 점수 는 식2 와 같이 계산된다. 이것은 기존 연구의 거리측정 metric에서 L2 normalization을 추가한 것임.
- : prototype
- : embedding output of
- ε : regularizing weight
- 또한, multi-label classification을 위해 standard binary cross-entropy사용.
- 모든 판례들은 를 통해 loss에 표현됨.
- 또한, 조문들은 를 통해 loss에 표현됨.
또한, 와 term에 대한 설명은 아래와 같다.

일단 의 다양한 term에 대해서 설명한다.
- 먼저 term을 보자.
- 에 대한 모든 prototype 집합인 에 대해, 를 해주고 있음
- 따라서, 이 term이 존재하는 이유는 ” 와 pair인 의 embeddings를 에 대한 prototype cluster 에 더 가깝게 하기 위함”
- term의 경우 term과 반대되는 역할을 가지고 있음.
- 와 pair인 의 embeddings를 에 관한 것이 아닌 prototype cluster 와 더 멀어지게 하기 위함
- 또한, term의 경우 같은 에 대한 cluster가 더 뭉쳐지게 하고 있음.
- 즉, 같은 에 대한 prototype 가 존재할 때, 이 둘의 유사도가 일정 크기(= ) 를 넘지 못한다면 punishing하기 위한 term임.
term 마찬가지로 다음과 같은 의미를 가진다.
- 와 pair인 의 embedding 와 에 대한 provision embedding 의 거리를 좁힌다.
4. Experimental Settings
4.1 Encoder Model Selection

- 위는 예비 실험 결과를 요약한 표이다. 모든 예비 실험에서는 vanilla fine-tunning을 사용하였다.
- 입력으로 case text만을 사용하면서, 사전 학습된 언어모델에 linear classification head(=그림 2에서의 )를 붙인 후 multi-class cross entropy를 통해 모든 파라미터를 fine-tunning시켰다.
- Legal BERT를 아키텍쳐로 선택
- RoBERTa보다 성능이 우수
- Longformer의 성능과 동등하면서 더 낮은 계산 비용을 가짐.
4.2 Dataset
- 미국 연방 법원 문서로 구성되어 있는 PACER court opinion dataset을 사용함.
- 총 175,741개의 문서로 구성되어 있음
- 각 opinion은 평균적으로 3.02개의 U.S Code provision(미국 법령 규정)을 인용함.
- 각 provision은 평균적으로 5308.51개의 citing opinions를 가지고 있음.
Expert Feedback
- PACER dataset과 prototype 발견알고리즘에 대해서 전문가의 의견을 얻었음
- RoBERTa로 훈련 세트를 인코딩하고 embedding을 clustering한 후, training set 중 cluster 중심에 가장 가까운 예제를 찾았음.
- 3명의 법률 전문가에게 4개의 예제와 그 예제들의 provision source text를 보여준 후, 해당 provision source text와 예제가 연관이 있는지 평가를 진행함.
- 총 3가지 척도로 평가 : 3은 매우 관련 있음 - 1은 완전히 관련 없음 결과는 아래와 같음

- 평균 1.5로, prototype의 관련성은 비교적 낮게 관찰됨.
- 후에 진행된 법률 전문가의 인터뷰에 따르면, 이는 target citations 에 의한 것으로 여겨짐.
- 논문에서는 인용의 빈도를 중요성의 표시로 선택했지만, 인용은 다른 목적으로도 많이 사용됨
- 위 실험에서 선택한 인용 중 많은 부분은 절차적인 부분임. 이러한 절차적 인용(procedural citations)은 법적 수수료 등을 정의할 수는 있지만 법적 논증과는 관련이 없음
- 이런 절차 관련 인용이 쓸모있는 예측이 아니였기 때문에, 전문가들은 낮은 평가를 주었음.
- 따라서, 법률 전문가의 지원을 받아 모델을 통해 선정된 상위 100개의 대상에 절차적 인용을 수동으로 제거하였음.
- 상위 100개 인용 중 55개가 절차적이였으며 상위 20개 중 15개가 절차적이였음.
4.3 surrounding Text Span Context
- LCP의 정의를 생각해보면, 이는 우리가 문서에서 인용과 관련이 있는 부분만 관심을 기울인다는 것을 알 수 있음. 이는 잠재적인 위법을 유발하는 사건의 경과에 관심을 가지는 것과는 다름.
- 또한, RoBERTa와 같은 모델에서 512token 제한은 긴 법적 문서를 parsing할때 걸림돌이 됨.
- 논문에서는 surrounding context는 사실에 기반하여 opinion과 argument를 포함하고 있기 때문에, 인용보다 더 중요하다고 생각하였음.
- 따라서 이러한 context를 고려하지 못하는 상황을 해결하기 위해, target citation의 surrounding context을 고려하기로 하였음.
- 즉, 인용 문장 전과 후의 n개의 문장을 가져옴.
- n = ±2인 경우 {..., s1, s2, sc, s3, s4, ...}에서 2개의 문장을 선택하여 결과적으로 총 5개의 문장을 유지
- ±2 context를 사용한다면 평균적으로 token limitation(ex, RoBERTa의 경우 512token)를 넘지 않음.
- 문서 내에서 target citation이 없는 경우, 최소 15개가 선택될 때까지 문장을 무작위로 추출
5. Results and Analyses
Baseline
이 실험의 목적은 input context로 제공할 주변 문장의 최적의 수를 결정하고 taget label의 개수가 성능에 미치는 영향을 조사하는 것.
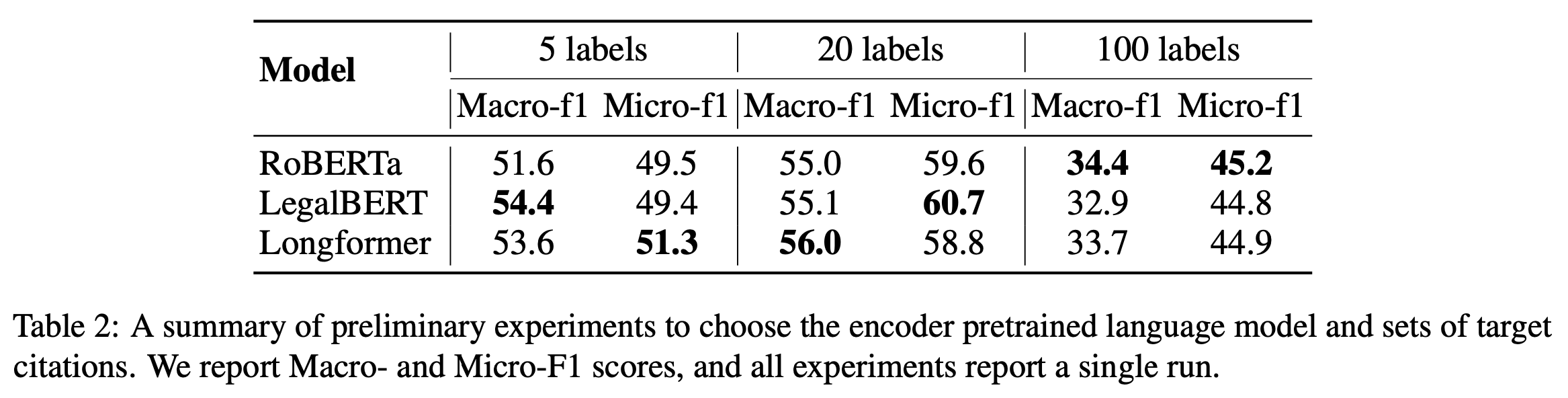
- 표 2를 통해 target label의 개수(=target citation의 개수)의 영향을 파악함.
- 5개 label보다는 20개 label이 더 나은 모습을 보임
- 100개 label로 갈수록 성능이 크게 감소
- 따라서, 20개와 100개 label로 실험을 진행.
- 4.2의 전문가 피드백을 기반으로 절차적 인용만을 포함하는 45개 레이블 설정을 추가
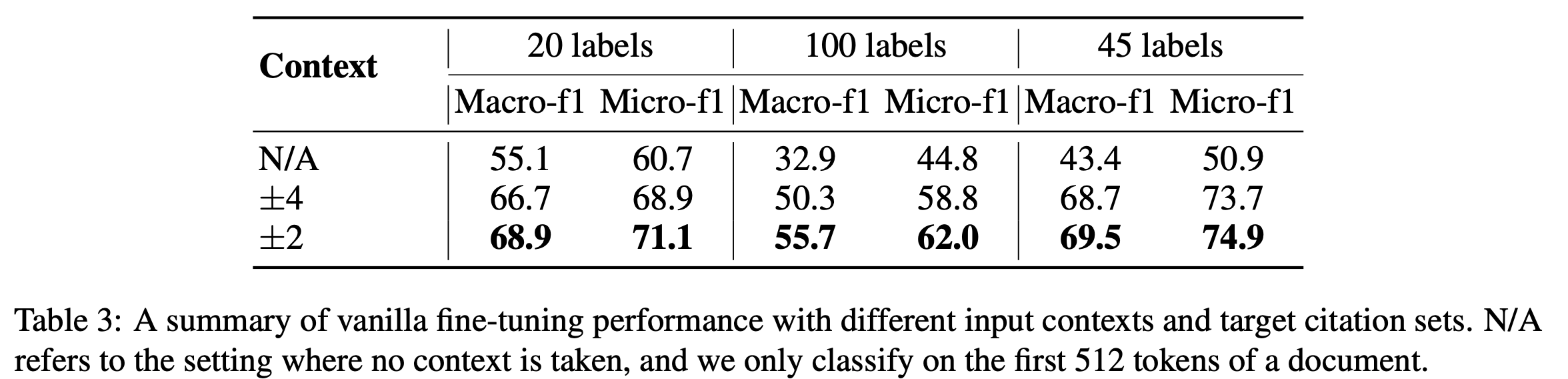
- 표3은 vanila fine-tunning 결과임. 이를 통해 input context로 제공할 주변 문장의 최적의 수를 결정
- ±2인 경우 최고의 성능을 보임.
- 100 lablel의 경우, 희귀 클래스가 늘어나서 성능이 낮아지는 것을 보임.
- 후속 실험에서는 20개 레이블을 기준으로 유지
- 또한 45 label의 경우 context를 제공했을 경우 다른 라벨들과 비교하여 상당한 성능향상이 생기는 것을 볼 수 있음.
- 이는 절차적 인용이 문서 첫 512 token내에 위치할 가능성이 크다는 것으로 해석됨. (table3는 문서의 첫 512 token을 classify한 것)
Prototype-based Model

- ±2 label을 사용한 baseline과 prototype-based Model을 비교 실험함.
- prototype-based Model의 경우 만 사용하였을 경우 baseline과 큰차이가 나지 않았음.
- 하지만 를 사용하였을 경우
- 20 label task(75% procedural citations)의 경우 baseline보다 우수한 성능을 보임
- 허나 45 label task 에서는 가 성능을 방해함.
Perturbations
- 조문(provision)사용의 효과를 알기 위해, 모델에서 여러가지 변화를 줌.
- 먼저 두 가지 설정을 시도
- Keyword Masking : 통계적 키워드 추출기인 YAKE를 사용해 입력 키워드를 [MASK]토큰으로 대체. provision text로부터 n=2까지 20개의 ngram을 추출.
- Random Masking : 입력 토큰의 15%를 무작위로 마스킹
- 키워드 마스킹의 경우 20 및 40 lablel 모두에서 무작위 마스킹 보다 모델 성능을 크게 감소시키나, 20 label에서 더 많이 감소됨.
- 이는 법적 논증과 관련이 없는 인용(=아마도 procedural citations) 이 그들의 source provision과 더 유사한 관계를 가지는 것을 의미함.( MASK는 procision text로 부터 추출되었으므로)
- 반면 법적 논증에 중요한 인용은 주변 문맥 및 다른 인용 문서와 더 추상적인 관계를 가지며, 이러한 인용을 provision text로 제한하는 것은 성능에 불리한 영향을 미침.
Vanilla Fine-tuning vs. Prototypes
- table4를 보면 latent space를 freezing하는 방법인 “Freezing Encoder”를 통해 Vanilla Fine-tuning vs. Prototypes을 비교.
- prototype discovery를 수행 → provision text encoding → prototype embedding이나 모델 파라미터를 업데이트하지 않으며 classification head 를 학습.
- 성능 하락이 1.0에서 6.3까지 일어나는데, 이는 prototype based loss를 이용하여 latent space를 재구성하면 점수가 1.0에서 6.3 증가한다는 것임.
- 학습 정보를 시각화 하기 위해 20 label model의 latent space를 투영시킨것은 아래의 그림과 같다.

- (b)가 시각적으로 더 잘 조직되어 있음을 알 수 있음.
- edge에 더 적은 outlier를 가지고 있음.
- 또한 다른 citations에 대응하여 명확한 case cluster를 가지고 있음.
- 또한 아키텍처를 더 자세히 조사한 결과, vanilla fine-tuning 이후에는 각 target citation에 대해 하나의 prototype만 발견되었음. 나머지 cluster 중심은 코사인 유사도 임계값을 충족하지 못하였음.
6. Conclusion
- 우리는 LCP(Legal Citation Prediction)이라는 문제를 연구
- 해석가능한 prototype 아키텍처를 설계하였음. 이 아키텍쳐는 모델의 결정을 [target citation]과 [판례 or 조문]의 유사성에 기반하여 설명함.
- 실험을 통해, vanilla fine-tunning과 비교하여 LCP가 동등한 성능을 내면서 더 많은 해석 가능성(interpretability)를 제공함.
- 또한 모델 훈련에서 판례와 조문의 조합을 활용하는 것이 baseline 언어 모델과 비교하였을 때 더 높은 성능을 보인다는 것을 입증함.
- 허나 성능은 target citation의 성격에 따라 달라짐.
Limiations
기술적이지 않은 내용들은 생략.
- 제시한 아키텍쳐는 가장 명백한 인용(the most obvious citations)을 찾으려고 함.
- 이는 더 쉬운 인용(=절차적 인용)에 대해서는 높은 성능을 보이나, 더 어려운 인용(=비절차적 인용)에 대해서는 낮은 성능을보이는 것과 연관이 있음.
- 이 문제를 충분히 해결하지 못함.
- 딥러닝 관점에서 보았을 때, main limitation은 k-means clustering에 의하여 생김.
- 훈련과정에서 불안정한 지점들이 관찰되었는데, 이는 k-means clustering의 초기화때문일 것이라고 예측됨.
- 만약 prototype이 초기화 된다면, loss function에서 이에 대응하는 term은 cross-entropy loss에 큰 영향을 주게 되고 이것은 model collapse까지 이어질 수 있음.
- 심지어 prototype이 적절하게 초기화 되더라도, 실 함수는 몇 번의 업데이트 후에 프로토타입에 과적합되지만 분류 성능을 향상시키는 않음.
- 이 때문에 validation에 validation loss대신 macroF1을 사용하여 best model을 선정한 것.
Ethics Statement
생략.
Uploaded by N2T