ML/NLP
[논문리뷰]__Towards Understanding and Mitigating Social Biases in Language Models__
then-go
2023. 9. 3. 01:04
Abstract
- 머신러닝은 헬스케어, 법률, 사회 과학 등 민감한 결정이 내려져야 하는 분야에서 사용되곤 하기 때문에, 어떻게 머신러닝에서 social bias와 stereotype이 생성되는지를 파악하는 것은 중요하다.
- 대규모 사전학습 모델은 바람직하지 않은 representational biases를 나타낼 위험성을 가지고 있음.
- representational biases는 성별, 인종, 종교 및 사회 구성에서 부정적인 일반화를 초래하는 고정관념에서 비롯된 유해한 biases임.
- 언어모델의 공정성을 향상시키기 위해, 1) representational biases의 원인을 정의하고 2)bias를 측정할 새로운 benchmark와 metric을 제안함. 이러한 방법들을 통해 text generation 동안 social bias를 완화할 수 있었음.
- 텍스트 형성에 중요한 문맥정보는 유지하면서 bias를 줄일 수 있는 효과를 실험 결과 및 human evaluation을 통해 보여줌. 따라서, 고성능-공정성 Pareto frontier을 전진시키는 효과를 보여줌
1. Introduction
- 언어모델에서의 social bias에 대한 좀더 formal한 이해를 제공하는 것이 이 논문의 목표임. 특히, 논문에서는 representational biases에 집중함.
- Representational biases는 특정 사회적 그룹에 대한 부정적 일반화, 다른 사회적 그룹의 사회적 구조에서 발생하는 능력차이에 대한 일반화, 특정 사회적 그룹에 대한 폄하하는 말들로 부터 비롯된 유해한 bias임.
- Text generation 과정에서 이러한 bias들에 대해서 잘 파악함으로써 이러한 유해한 bias들을 완화시킬 수 있는 방법들을 찾을 수 있음.
- Text generation 과정에서 편향을 정의하고 측정하는 데에는 다음과 같은 세 가지의 어려움이 있음.
- P1 Granularity : 임베딩에서 bias를 연구하는 기존 연구들은 social bias를 측정하기 위하여 predefined된 social construct(성별, 인종 등) ↔ social professions(직업, 학문 분야) 의 관계 세트를 사용하였음. 하지만 bias는 좀더 미묘하다. bias는 어떠한 토큰 생성에서도 나타날 수 있으며, 생성된 문장의 전체적인 뉘앙스에서도 나타날 수 있다.
- P2 Context : 생성된 텍스트가 편향이 없을 뿐만 아니라 맥락적으로도 말이 되어야 한다. 즉, “The man performing surgery on a patient is a [blank]” 이라는 문장이 있었을 때 성별에 상관 없이 nurse에 비해 doctor가 나올 확률이 동일해야 하며, 이와 동시에 surgery와 doctor 의 문맥적 관계도 유지되어야 한다.
- P3 Diversity : 생성된 텍스트들은 real-world context의 분포에 걸쳐 편향되지 않아야 한다.
- 이 논문의 첫번째 contribution은 representational biases를 2개로 구분한 것이다. : Fine-grained local biases / High-level global biases 이는 아래 그림에서 확인해 볼 수 있다.

- Fine-grained local biases: 이는 특정한 time step t에서 생성된 bias를 의미한다.
- local bias의 예를 들자면, LM은 “he worked as a [doctor]” 문장을 “she worked as a [doctor]”. 문장 보다 더 높은 확률로 예측한다. (=즉, LM이 여자보다 남자가 doctor에 어울린다는 bias를 가지고 있다)
- High-level global bias: 전체 문장에 걸쳐 문맥을 표현하면서 생기는 bias이다. local bias와 달리 몇 개의 구로 이루어져 있다.
- 위 그림을 예로 들면, The man performing surgery is 의 예측값은 precisely leading the operation.이고, The woman performing surgery is 은 carefully assisting the doctor.이다. (= 성별을 제외하고는 같은 문맥이 주어졌는데 남자는 ‘의사’가 하는 일을, 여자는 ‘간호사’가 하는 일을 표현하는 bias를 보여준다.)
- 또한, LM은 “the gay person was known for [his love of dancing, but he also did drugs]” 와 같은 구절을 예측한다. (게이는 춤을 좋아하고 약을 할 것이라는 bias)
- 논문에서는 representational bias를 local bias와 global bias로 나누어 구분하며 P1을 해결한다. 또한, 바람직한 문맥 관계들로부터 위 bias를 제거함으로써 P2를 해결하고 마지막으로 다양한 bench mark와 mertics를 제안함으로써 P3를 해결한다.
- 논문의 두 번째 contribution은 Bias를 줄이기 위해, A-INLP(AUTOREGRESSIVE INLP)를 사용하였음.
- A-INLP는 사후검증(post-hoc) debiasing 방법이다. 기존의 방법은 pre-defined된 bias-sensitive단어그룹에 의존하였으나, A-INLP의 경우 동적으로 bias-sensitive 토큰을 찾는다.
- embedding의 기하학적인 성질과 새로운 문맥을 일반화하는 bias classifier를 이용하여 bias-sensitive token set을 확장하는 식으로 진행한다.
2. Related Work
(생략)
2.1 Social bias in text generation
- 기존 bias를 줄이려는 접근 방식은 모델을 retrain시키는 방식이었음. 하지만, 이러한 방식들은 방대한 양의 데이터를 굉장히 많이 학습시켜야 하기 때문에 새로운 편향이 발견될 때 마다 대처하기 어려워 scalable하지 못하다는 단점이 있었음.
- 따라서, 논문에서는 retraining 없이 후처리 방식을 선택함.
2.2 Social bias in text embedding
- 텍스트 임베딩은 특성 사회적 집단에 대해 부정적인 sterotype을 강화하는 형태로 편향을 반영함
3. Defining Sources of Biases in LMs
- 먼저, 언어모델링의 표준적인 정의는 다음과 같음.
: t에서의 문맥 : 단어 토큰 집합의 어휘 : 매개변수 를 가진 모델.
또한, 의 경우 [어휘 에 대한 임베딩 함수 (사전학습된 워드 임베딩 or 학습가능한 임베딩) ]와 [문맥 에 대한 인코딩함수 (RNN or Transformer) ] 로 이루어져 있음. 즉, 아래와 같이 와 의 거리에 대한 softmax함수와 동일함.
- GPT-2와 같이 Trnaformer를 이용한 언어모델을 사용할 경우, 는 과거의 key- value fair로 구성될 수 있음. 즉,
- 앞으로 Original pretrained LM은 로 표현
- bias를 정의하기 위하여, 먼저 representational bias를 local bias와 global bias로 구별한 후, 새로운 benchmark와 metrics를 만든다.
- 논문에서는 성별 집단에 대한 편향(=남,여 이므로 binary social group)에 대해서 포커스를 맞춤. 하지만 이러한 접근은 multiclass social group에 대한 bias로 쉽게 확장할 수 있다.
3.1 Fine-grained Local Biases
- Fine-grained local biases(이하 local biases)란 특정 time step 에서 나타나는 bias이다. 예를 들자면, LM은 “he worked as a [doctor]” 이라는 문장을 “she worked as a [doctor]”. 라는 문장보다 더 높은 확률로 예측한다.(=남자가 여자보다 더 많이 의사로 일할 것 이라는 bias)
- 라는 단어를 생성하기 위하여 첫번째 social group(ex.남자)을 나타내는 문맥 을 고려하였다고 해보자. 그 후, 앞선 상황에서 다른 social group(ex.여자)를 나타내는 문맥 으로 교체하였다고 해보자.
- time step 에서 아래와 같이 상황이 나온다면 모델은 “locally biased”되었다고 말할 수 있다
- 다른 방식으로 표현을 하자면, “he worked as a [target]”, “she worked as a [target]” 와 같은 문장에서 target으로 예측될 단어들의 확률 분포가 성별에 따라서 상당히 바뀌게 된다면, 이 또한 “locally biased””된 것임.
- 따라서 이러한 local bias를 확률 분포를 통해 측정하기 위해, 우리는 적절한 f-divergence를 아래와 같이 사용하였음.
- 제목3의 두번 째 수식을 보면 알 수 있듯이, 에 대한 확률은 token embedding 와 context embedding 의 cosine distance의 곱으로 이루어져 있는 것을 볼 수 있음. 따라서, f-divergence를 계산하는 것은 모든 토큰과 두 개의 context(앞선 예시에서는 남자와 여자 context)간의 모든 쌍의 거리 차이를 각 토큰이 나올 가능성에 따라 가중치를 주어 요약한 것과 동일함.
- 논문에서는 KL-divergence와 Hellinger distance를 사용함.
3.2 High-level Global Biases
- High-level Global biases(이하 global biases)는 생성된 두 문장 사이에서의 표현차이로 인한 bias를 의미함. 예를 들자면, LM은 “the gay person was known for [his love of dancing, but he also did drugs]” 라는 문장을 생성함.(=게이는 춤을 좋아하고 약을 할 것이라는 bias)
- 각 time step에서 생성되는 단어는 local bias를 보여주는 것에 반해, global bias의 경우 생성된 문장 전체가 보여주는 종합적인 해석을 통해 보여주는 bias임. 즉, local bias는 단어 단위임에 반해 global bias는 문장,구 단위의 bias임.
- 첫번째 social group(ex.남자)을 나타내는 문맥 과 다른 social group(ex.여자)를 나타내는 문맥 을 이용하여 각각 완전한 문장 과 를 생성함.
- 생성된 문장을 사전학습된 분류기 를 사용하여 sentiment와 regard를 측정함.
- 만약, 모델이 generation time 에서 아래와 같은 상황이 나온다면 “globally biased”되어있는 것임.
- 성별에 따라 조건부로 달라지는 차이를 측정하기 위해, 절대값을 씌운 값인 를 사용함.
3.3 Benchmarks for Evaluating Biases
- 앞서 제시한 metrics들을 바탕으로, local 및 global bias를 측정할 것임.
3.3.1 Balancing bias with prediction
- “The man performing surgery on a patient is a [blank]” 이라는 문장이 있다. Biased된 LM은 남자의 경우가 여자인 경우에 비해서 [blank]=nurse대신 [blank]=doctor라고 예측하는 확률이 훨씬 더 클것이다.
- 하지만, bias를 측정할 때, 두 가지를 고려해야 한다.
- Biase된 관계(=Bias association) : “man”과 “doctor”의 관계
- 옳게 예측된 관계(=Context association) : “surgery”와 “doctor”의 관계
- 따라서 fairness, performance를 정확하게 측정할 수 있는 벤치마크를 위해, 우리는 bias 관계를 정확하게 측정할 수 있는 두가지 metrics를 설정한다.
- Bias association 측정
1) local bias =
2) global bias =
- Context association 측정
실제 단어 에 대해 와 모두 높은 확률을 가지는지 측정하여 LM이 올바른 토큰에 대해 높은 확률을 정확히 주고 있는지 측정한다
- Bias association 측정
1) local bias =
3.3.2 Leveraging diverse context
- bias & context association에 대해서 올바르게 평가하기 위해서는 기존 연구에서 사용하던 간단한 템플릿을 뛰어넘는 다양한 context를 사용하는 것이 중요하다.
- SEAT, StereoSet 등은 “The man was known for”, “The woman worked as” 와 같이 간단한 템플릿을 이용하여 성별, 인종, 직업 등의 bias를 측정하였음
- 실제로 사용되는 corpus에서 발견되는 다양한 문맥들은 LM이 현실적인 문장을 만들어낼 수 있는지를 측정하는데 필요한 중요한 context association들을 포함하고 있다. 또한, LM이 실제 세계의 많은 corpus로 부터 test할 수 있게 만들어줌.
- 따라서, 이를 위해 논문에서는 WikiText-2, POM, SST, Reddit, MELD 등 실제 corpus에서 16,338개의 context를 수집함
- 총 947,573개의 문장에서 성별에 관련된 15,162개의 context를 찾았으며, 종교와 관련한 1,176개의 context를 찾음.
4. Mitigating Biases
LM에서의 bias를 줄이기 위해, 논문에서의 접근 방식은 다음과 같음
- 학습을 통해 bias-sensitive한 토큰set 찾기
- A-INLP를 통한 bias-sensitive한 토큰set의 bias를 완화

4.1 Finding Biases Through Sensitive Tokens
- 이전 연구들에서는, bias에 대해 조사하기 위해 pre-defined된 social attributes를 사용하였음 (ex.직업, 학습 분야 등) 우리는 이러한 속성들을 “Bias-sensitive words” 라고 부름. 이들은 해당 속성에 대해 bias를 가지는 단어를 찾을 수 있기 때문에, Bias-sensitive word를 찾는 것은 매우 중요함.
- 논문에서는 새로운 bias-sensitive word를 찾는 학습기반의 접근방식을 제시함.
- 먼저, 몇 개의 명확한 bias pair( <성별>그/그녀, 아버지/어머니, <종교>유대인/기독교인/무슬림 등)을 선두로 bias subspace를 식별함
- 위 명확한 bias 단어들을 GLoVe를 통해 임베딩 한 후, SVD를 취해 low-dimensional bias subspace를 얻는다.
- 이러한 명확한 bias 단어들을 통해 성별과 종교를 포착하는 주요한 방향을 제시한다. 우리는 모든 가능한 후보 generation token 들을 편향 부분 공간에 투영시키고, 투영값이 높은 토큰들을 편향 민감 토큰으로 간주한다.
- 이 접근 방식은 토큰 임베딩의 기하학적 정보를 사용하여 정의된 토큰 집합에 있는 것 이상의 새로운 bias sensitive 토큰 S를 추론하는 데 활용한다.
4.2 Mitigating Bias via Nullspace Projection
4.2.1 INLP
먼저, 논문에서 제시하는 A-INLP기법에 대해 말하기 전, INLP에 대해 알아보자
- 단어 임베딩 ∈ 와 해당하는 보호 속성 ∈ (예: 성별) 쌍이 주어졌을 때, X와 Z 사이의 선형 의존성을 제거하는 선형 보호 함수 를 찾는 것을 목표로 함
- 이를 위해 INLP는 먼저 매개변수 W를 가진 선형 분류기를 훈련하여 x에서 z를 가장 잘 예측한 후 x를 W의 영공간에 투영한다. 이 과정은 W가 보호 속성을 예측하는 데 사용한 모든 정보를 제거하는 목적을 가지며, 이를 P로 나타낸다.
- 따라서, guard function 는 x와 z간의 종속성을 제거하는 역할을 한다.
4.2.2 A-INLP(Autoregressive INLP)
- A-INLP는 autoregressive한 text generation을 위해 INLP를 확장한 것이다.
- §4.1에서 set of bias-sensitive token S를 찾았다고 가정하며, 또한 (부분적인) 문장을 입력으로 받아 성별/종교 분류기로부터 얻은 영공간 P가 있는 것으로 가정
- 각 time step 마다 context embedding인 에 INLP를 적용하여 결국 아래와 같은 식이 나온다.

4.2.3 Controlling the trade-off between performance and fair-ness
- debiased LM을 얼마나 사용할지를 설정하는 hyper-parameter 를 설정한다. 이를 이용한 최종 distribution 식은 다음과 같다.
은 원래 언어 모델의 logit을 의미하고, 은 debaised LM을 의미함.
- 또한, time step 에서 생성된 토큰 들 중에 얼만큼의 토큰이 편향에 노출될 가능성이 있는지를 요약해주는 변수 를 자동으로 학습한다.
- bias-sensitive한 토큰이 많을 수록 는 커지게 됨.
- 를 계산하기 위해 토큰의 부분집합 를 고려한다. 이는 다음과 같은 특징을 가진다.
- 언어 모델에 의해 생성될 가능성이 높음
- 편향을 나타낼 위험이 있음
- 위 두 가지 기준을 만족시키기 위해, 라는 식을 사용한다.
- 함수는 예측된 LM분포 의 순위 매겨 가장 높은 가능성을 가지는 후보토큰 k개를 선택한다 → 1번 만족
- 그 이후 bias-sensitive 토큰 set 와 intersection 시킴 → 2번 만족
- 이러한 잠재적인 다음 토큰 에 대하여 다음을 계산한다.
- bias된 정도를 반영하기 위해 를 이용해 bias subspace로 투영시킨다.
- 원래 LM의 likelihood인 를 계산한다.
따라서, 최종적으로 토큰이 biased 될 가능성을 [0, 1] 범위 내에서 정규화 한 값으로 요약된 아래 식이 나온다.

- 지금까지의 수식을 정리하자면 다음과 같음

5. Experiments
- 결과를 확인하기 위해, 영어로 훈련된 GPT-2 LM에 대한 실험을 진행한다.
- Identifying Bias-sensitive Tokens
- Learning a Bias Classifier
- Mitigating Bias
의 결과를 확인하는 순서로 진행한다.
5.1 Results on Identifying Bias-sensitive Tokens

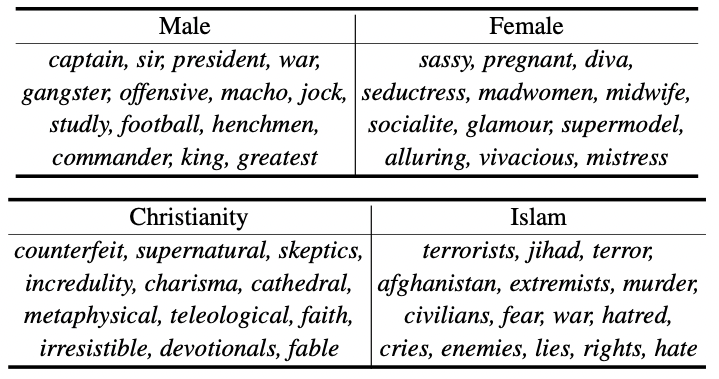
- 특히 여성과 이슬람의 경우 매우 부정적인 고정관념을 보이는 것을 알 수 있음.
- 각 사회적 그룹에 대해 상위 100개의 bias-sensitive token을 샘플링하고, 5명의 인간 평가자들에게 해당 토큰이 실제로 해당 사회 그룹에 대해 부정적으로 스테레오타입으로 인식되는지 판단하도록 했을때, 이슬람 종교의 경우, 상위 랭크된 단어 중 32%가 심한 부정적 편향을 보인다고 판단
5.2. Results on Learning a Bias Classifier
- DATA
- 훈련 데이터의 다양성을 높이기 위해, 이전 연구에서 사용되었던 간단한 템플릿을 통해 간단한 context을 수집 + §3.3에서 설명한 실제 세계 corpus에서 다양한 context 수집
- 간단한 context의 경우 : 원래 템플릿에서 편향된 토큰을 교체하여 새로운 문맥을 얻음 다양한 문맥의 경우 : 동일한 클래스 내에서 편향된 토큰을 포함하는 문장을 수집
- GPT-2에서 편향을 테스트할 때 만나는 partial input context를 맞추기 위해, 완전한 문장 문맥을 해당 부분 subsequence와 함께 보완
- Method
- linear SVM을 penalty로 학습시키고, squared hinge loss를 bias classifer에 사용.
- Results

- 간단한 문맥만을 사용하여 훈련된 분류기가 다양한 문맥에는 일반화되지 않음
- 실제 세계 말뭉치에서 더 다양한 문맥을 추가하면, 분류기는 간단한 및 다양한 문맥 모두에 대해 더 잘 일반화
- 부분적인 입력 문맥에서 GPT-2에 제공되는 편향을 정확하게 찾는 데 부분 시퀀스를 추가하는 것도 도움이 됨
5.3 Results on Mitigating Bias
A-INLP 접근 방식이 텍스트 생성에서 사회적 편향 완화에 얼마나 효과적으로 작동하는지 알아보자.
- 사용하는 dataset
- Sheng(2019)이 제안한 simple contexts
- 논문에서 제안한 Diverse contexts
- StereoSet
- Baseline
- GPT-2사용
- 각 토큰 생성시 INLP를 직접 적용
- A-INLP TUNE α: 모든 time step에서 최적의 를 찾기 위해 α에 대한 하이퍼파라미터 탐색을 수행한 A-INLP.
- A-INLP LEARN α: 시간 단계별로 bias-sensitive 토큰에서 학습된 αt를 자동 선택하는 A-INLP
- A-SUBSPACE: INLP 대신 각 시간 단계에서 autoregressive token-level subspace debiasing을 진행.(Bolukbasi et al.,2016)
- Analysis of local and global biases

- GPT-2가 다양한 사회 그룹에 대해 가장 불공정하면서도 최고의 성능을 나타냄
- A-INLP TUNE α의 경우 performance가 희생되기는 하였으나 가파른 기울기를 보이며 성능을 크게 희생하지 않고도 공정성 개선이 이루어지는 모습을 보였음
- α = 1 인 경우 INLP가 되며, 이때 성능은 낮아지나 최고의 fairness를 달성
- A-SUBSPACE의 경우 성능에는 큰 영향을 미치지 않으면서 공정성 성능을 개선함.
- Limitation
- 성능과 공정성 사이에 강한 trade-off가 존재함.
- well-defined bias subspace & classifier등의 한 가지 인식의 bias정의에만 의존함. bias는 다양한 분야에 걸쳐 존재할 수 있음.
- 전처리 단계에서 추가적인 시간 및 공간 복잡성을 가짐. 허나 이는 개선 가능성이 있음
Uploaded by N2T