1. Word Embedding
먼저, 임베딩의 의미부터 살펴봅시다.
- 임베딩이란: 사람이 쓰는 자연어를 기계가 이해할 수 있는 숫자의 나열인 벡터로 바꾼 결과 혹은 그 과정을 의미합니다.
사람이 사용하는 단어(=자연어)는 0과 1로 이루어진 단어가 아닙니다. 그렇기에 컴퓨터 입장에서는 자연어의 의미를 이해하기가 어려운데요, 자연어의 특징을 추출해 수치화(=word vector로 만드는 것)를 해주는 것이 Word Embedding이라고 볼 수 있습니다.
자연어의 특징을 ‘어떻게’ 추출하는 지에 따라서 embedding의 종류가 나뉘게 되는데요, word embedding의 발전 과정을 따라 쭉 따라가 보겠습니다.
1.1 One-Hot Encoding
one-Hot Encdoing이란?
one-hot encoding은 단어를 one-hot vector로 바꾸는 것입니다. one-hot vector는 전통적인 NLP에서 사용되었던 방법으로, 간단한 예시를 들어보자면 다음과 같습니다.
"나는 학교를 다닌다"라는 문장이 있다고 생각해 봅시다. 그러면 단어를 크게
['나', '는', '학교', '를', '다닌다']이런식으로 나눌 수 있을 것이고, 각각의 단어에 ‘1’의 자리를 할당하는 것입니다. 즉,
'나' = [1,0,0,0,0]
'는' = [0,1,0,0,0]
'학교' = [0,0,1,0,0]
'를' = [0,0,0,1,0]
'다닌다'= [0,0,0,0,1]그냥 단어 하나 하나 마다 1이 들어가는 공간을 할당해 놓고, 그것으로 단어를 구분하는 것입니다.
그런데 one-hot vector는 치명적인 단점을 가지고 있습니다. 아래를 보시죠.

크게 두개의 문제로 나눌 수 있는데
- vector의 dimension이 모든 단어의 개수만큼 나와야 한다는 것.(그럼 하나의 벡터가 차원이 아주 커질것이다)
- 단어들간의 유사도를 표현하기 힘들다.
1에 대해서 얘기해보자면, 벡터의 차원은 매우 커지는 것에 비해, 큰 차원들 중 하나만 1일 것이고 나머지는 전부 0일 것입니다. 우리는 이러한 벡터 표현 방법을 희소표현(sparse representation)이라고 합니다. 공간적 낭비가 심하다는 단점이 있습니다.
2에 대해 예시를 들자면, 구글링 할때 “Seattle motel”을 검색한다면 “Seattle hotel”또한 우리가 원하는 정보일 것입니다.(특히 요즘처럼 모텔과 호텔을 구분하지 않는 세상이라면…)
하지만 위 벡터를 보시죠. 두 벡터는 orthogonal입니다. 따라서, model과 hotel은 매우 유사한 단어임에도 one-hot vector로 표현시 유사성을 찾기는 어렵습니다.
1.2 Word embedding
word embedding이란 단어를 one-hot vector가 아니라 밀집벡터(dense vector)로 표현하는 방법입니다. 그렇다면 dense vector는 무엇일까요?
- Dense vector란?
아까, one-hot vector에서는 문장(혹은 문서)내의 단어의 개수만큼 차원이 확장되어야만 했습니다. 예를들어 문서에 10,000개의 단어가 나온다면 one-hot vector로 표현한다면 아래와 같을 것입니다.
"hotel" = [0,1,0,0, ....... ,0] #"hotel"벡터의 크기는 10,000하지만, dense vector에서는 사용자가 차원을 지정해주고, 그에 따라서 벡터를 만들어줍니다. 그리고 더 이상 0과 1만 사용하는 것이 아니라, 실수값으로 벡터를 표현하게 됩니다. 예를 들어서 dense vector의 차원을 128로 정했다면 아래와 같이 표현됩니다.
"hotel" = [0.3,1.2,-0.4,1.6, ....... ,0.2] #"hotel"벡터의 크기는 1280과 1이 아닌 실수로 단어로 표현하기 때문에 더 적어진 차원으로도 충분히 단어를 표현할 수 있습니다. 차원이 조밀해졌다고 하여 밀집벡터(Dense vector)라고 부르게 됩니다.
- word embedding의 장점
- 앞서 표현했던 것처럼, 문서의 단어 수만큼 차원이 늘어나야 했던 one-hot vector와 달리 차원을 임의로 정하여 단어를 표현할 수 있습니다.
- 단어들간의 유사도 표현이 가능해집니다. 앞서 예를 들었던 hotel과 motel을 예로 들자면, 이 둘은 문장에서 문맥상 혼용되는 경우가 많으므로 이 두 단어는 굉장히 유사할 것입니다. 즉, 두 단어의 word vector는 벡터 공간에서 비슷한 위치에 있을 것입니다.(코사인 유도사도 또한 1에 가까울 것입니다)
이러한 워드임베딩 방법론에는 Word2Vec, Glove, FastFive등이 있습니다. 그럼, 하나하나씩 알아볼까요?
1.3 Word2Vec
Word2Vec은 크게 두가지 방법으로 나눌 수 있습니다. 바로 CBOW(Continous Bag of Word)와 Skip-Gram입니다.
- CBOW: 주변에 있는 단어들을 입력으로 중간에 있는 단어들을 예측
- Skip-Gram: 중간에 있는 단어를 입력으로 주변에 있는 단어들을 예측
이 둘의 메커니즘은 거의 동일하므로 CBOW에 대해서 자세하게 설명하고, Skip-gram의 경우 CBOW와의 차이점을 기준으로 설명할 예정입니다.
1.3.1 CBOW
앞서 말한 대로 주변의 단어들을 입력으로 중심에 있는 단어을 예측하는 방법입니다. 예시를 들어보겠습니다.
"The fat cat sat on the mat" #예문
['The', 'fat', 'cat', 'on', 'the', 'mat'] #단어 단위로 나눴을 경우이라는 예문이 있다고 합시다. 먼저, 용어 정의를 하고 들어갑시다
- 주변단어(context word):입력으로 넣어줄, 예측에 사용되는 단어들
- 중심단어(center word):우리가 예측할 단어
- 윈도우(window): 중심단어를 예측하기 위해 넣어줄 중심 단어 양쪽의 주변단어의 범위(중심단어와 주변단어를 찍어내는 틀이라고 생각하면 편함)
- 슬라이딩 윈도우(sliding window): 윈도우를 움직여가며 주변 단어와 중심 단어의 데이터셋을 만드는 것
그러면, 슬라이딩 윈도우를 통해 주변단어와 중심단어를 뽑아 봅시다. 참고로 윈도우의 크기는 2입니다(=하나의 중심단어에 양 옆으로 2개의 주변단어가 뽑히게 됩니다)

cf)단어 자체는 one-hot vector로 표현됩니다. 참고로, 여기서는 그냥 one-hot vector로 입력을 넣어 주었을 뿐이고, 모든 word2vec이 input으로 one-hot vector를 쓰지는 않습니다. 그냥 dense vector를 넣어주는 경우도 있습니다.
우리는 주변단어로 중심단어를 예측하기 때문에, sat이라는 중심단어를 예측한다면 아래와 같은 구조를 가집니다.(아래는 window size = 1)
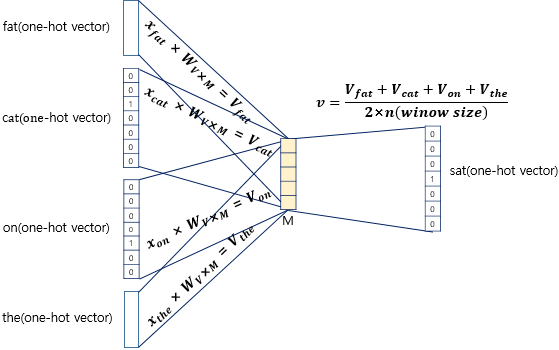

- =input vector의 차원
- =투사층의 크기
구조에 대해 간단하게 설명하면, 인풋에 를 행렬곱 해주어 임베딩 벡터를 만들고, (input 임베딩 벡터들의 평균값)과 를 행렬곱 해주어 output값인 을 만들어 준 후, 그 를 softmax함수에 넣어 다음 값으로 올 확률인 를 예측하는 과정입니다. 그 후, 은 정답인 와의 오차를 줄여가는 식으로 학습을 진행합니다.
와 의 오차를 줄이기 위해서 CBOW는 손실 함수(loss function)로 크로스 엔트로피(cross-entropy) 함수를 사용합니다. 크로스 엔트로피 함수는 아래와 같습니다.

참고 및 증명
코퍼스가 T개의 단어를 가지고 있다고 하면, 다음과 같이 확장시킬 수 있습니다.
Likelihood

- 여기서 theta는 최적화할 변수를 나타냄.
- t는 중심단어(c)의 위치를 나타내고, T는 전체 코퍼스의 크기를 나타냄.
- 설정한 window size만큼 주변단어(o)를 파악해, 중심단어(c, index=t)가 있을때 주변단어(o)가 나올 확률을 구함.
- 이걸 t=1 ~ t=T까지 돌리는 것
Objective Function(손실함수)
손실함수는 cost, loss라고도 불리는데, 낮을 수록 좋음.(Likelihood는 높을수록 성능이 좋음!)

- scale에 대한 의존을 줄이기 위해 T로 나누어주어 scale을 줄여준다.(normalize)
- 곱셈→덧셈으로 바꾸기 위한 log씌워주기.
자, 식은 알아보았고 그러면 식을 어떻게 계산할지 알아보자
식계산하기(증명)
중심단어(c)(Vc)가 있을때 주변단어(o)(Uo)가 나올 확률은 다음과 같다.

- dot product(내적)은 벡터의 유사도를 계산한다. 즉, 내적의 값이 크면 비슷한 벡터이다. 중심단어와 주변단어를 내적해 두 벡터의 유사도를 계산
- exp는 무슨 값이든지 positive로 만들어줌
- normalize(scale에 대한 의존을 줄이는것)을 위해 전체 단어와 중심단어를 내적한 합을 나눠줌
이건 Softmax함수와 똑같이 생겼다.

softmax함수는 큰 확률을 더 크게(max)만들고, 작은 확률에는 더 작은 확률을 할당(soft)하기 때문에 생겨난 이름이다.
자, 이제 목표인 손실함수 최적화를 진행해야한다.(optimization 이라고 부름). 아까 theta(=word vector)가 optimized되어야한다고 했으므로 목표단어인 중심단어(Vc)로 편미분을 진행한다.

즉, observed(실제 문맥 단어) - expected(예측 문맥 단어)의 차이가 적을 수록 성능이 높아진다. 따라서 이 수식이 최소화되는 방향으로 학습을 진행하면 된다.
중요한 점은 theta는 두 가지의 벡터값을 지니고 있다는 사실을 잊지말자!
즉, CBOW의 구조에서는 와 를 학습시켜 word embedding을 진행시킨다고 생각하면 됩니다.
인풋으로 one-hot vector를 넣어주었으니, 사실 embedding하는 과정은 아래와 같이 의 번째 행을 가져오는 것과 동일합니다. 그래서 이 작업을 룩업테이블(lookup table) 이라고 합니다. 결국 의 행벡터가 word2vec 학습 후 각 단어의 M차원의 임베딩벡터로 간주되기 때문입니다.
1.3.2 Skip-gram
CBOW는 주변 단어로 중심 단어를 예측했다면, Skip-gram은 중심단어를 인풋으로 주변단어를 예측합니다. 이 외에는 모두 동일한 과정을 거칩니다.

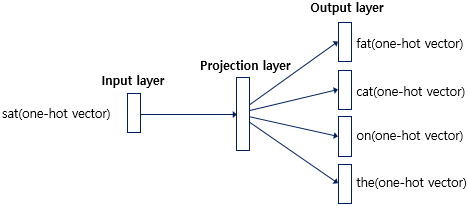
평균적으로 CBOW보다 skip-gram이 성능이 더 좋다고 알려져 있습니다.
1.2GloVe
- 기존의 카운트 기반의 LSA(Latent Semantic Analysis)는 전체 코퍼스의 통계정보를 통해 단어의 의미를 파악하나, 이는 왕:남자 = 여왕:? (정답은 여자)와 같은 단어 의미의 유추 작업에는 성능이 떨어졌습니다
- 예측기반 Word2Vec은 단어 의미의 유추 작업에는 높은 성능을 보였으나, window를 설정해 중심단어 좌우의 몇 개의 단어들만 고려하였기 때문에 코퍼스 전체의 문맥 또는 통계정보를 반영하지 못한다는 단점이 있었습니다.
글로브는 GloVe(Global Vectors for Word Representation, GloVe)의 약자로, LSA와 Word2Vec의 단점을 상쇄하고자 나온 방법론입니다. 즉, 이 두 가지 방법론을 둘 다 사용합니다.
다만, 현재까지의 연구는 Word2Vec과 GloVe의 성능은 비등하다고 하니, 상황에 맞게 잘 사용하시면 되겠습니다.
1.2.1 윈도우 기반 동시 등장 행렬(Window based Co-occurrence Matrix)
co-occurrence matrix는 문서 전체나 단락에 대해서 수행하면서 등장하는 단어의 수를 세는 것입니다. 문단 단위로 행렬을 생성한다면 주제에 대해서 의미 분석이 가능합니다. 예시를 들어보죠.
- 예시 문장
- I like deep learning
- I like NLP
- I enjoy flying
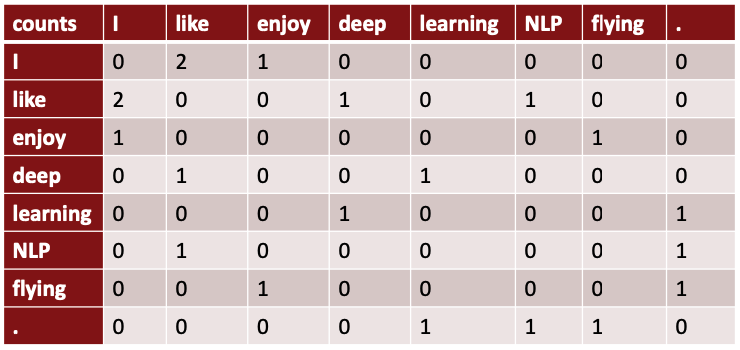
위 행렬로부터 co-occurrence를 생성할 수 있습니다. 만약 큰 말뭉치에 대해 ‘you’가 들어간다면 위 세 문장에서 ‘I’의 자리에 ‘you’로 대부분 바꿀 수 있으므로 비슷한 co-occurrence값을 가질 것이며, word vector도 비슷한 값을 가질 것입니다.
1.2.2 동시 등장 확률(Co-occurrence Probability)
동시 등장 확률 는 동시 등장 행렬로부터 특정 단어 i의 전체 등장 횟수를 카운트하고, 특정 단어 i가 등장했을 때 어떤 단어 k가 등장한 횟수를 카운트하여 계산한 조건부 확률입니다. 아래를 보시죠
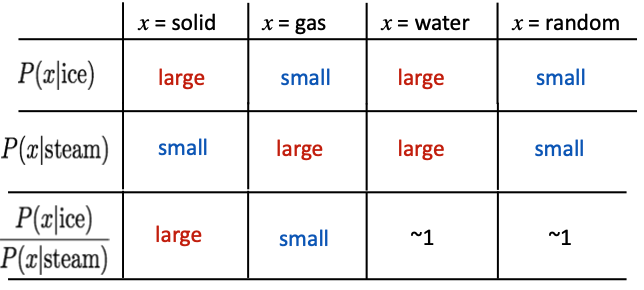
- water은 ice와 stream이 중심단어일 때 둘 다 많이 쓰이는 단어입니다. 따라서 와 의 값은 큽니다.
- 반대로, random의 경우는 ice와 steam모두 같이 쓰일 확률이 적으니 반대의 양상을 보입니다.
- solid는 기체인 steam보다는 고체인 ice와 더 많이 쓰일 것입니다. 따라서, >> 입니다.
- 반대로, gas는 고체인 ice보다는 기체인 steam와 더 많이 쓰일 것입니다.따라서 << 입니다.
같이 나오는 단어들을 통해 단어의 의미가 조금씩 파악이 되는 것이 느껴지시나요?
GloVe의 아이디어를 한 줄로 요약하면 '임베딩 된 중심 단어와 주변 단어 벡터의 내적이 전체 코퍼스에서의 동시 등장 확률이 되도록 만드는 것'입니다. 즉, 이를 만족하도록 임베딩 벡터를 만드는 것이 목표입니다. 이를 식으로 표현하면 다음과 같습니다.


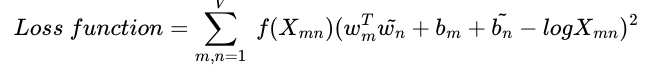
결론만 말하자면, loss function은 다음과 같습니다.
유도 과정은 아래에 있습니다. 늙어서 그런가 손으로 쓰는게 이해에 좋네요..




1.3 FastText
또 다른 방법으로는 facebook에서 개발한 FastText가 있습니다. Word2Vec의 확장판이라고 생각하면 편합니다.
Word2Vec과 FastText의 가장 큰 차이점은
- Word2Vec: 단어를 쪼개질 수 없는 단위로 생각
- FastText: 하나의 단어 안에도 여러 단어들(subword)이 존재하는 것으로 생각.
1.3.1 subword의 학습
subword는 총 두 가지 측면에서 학습됩니다. 먼저 단어에 단어의 시작과 끝을 의미하는 <,>를 붙이고 subword를 나눕니다.
- 글자 단위 n-gram으로 subword생성
- 기존 단어 그 자체로 subword 생성
n-gram에서 n=3으로 잡은 예시를 들어봅시다.
"apple"= <ap, app, ppl, ple, le>, <apple>근데 실제로 사용할 때는 n의 최소값과 최대값을 정해놓고 사용합니다. 즉, n=3~6인 경우
"apple"= <ap, app, ppl, ppl, le>,
<app, appl, pple, ple>,
<appl, pple>, ..., <apple>이런 식으로 구성되게 됩니다.
이렇게 단어를 학습하면 단어를 ‘어근’단위로 학습이 가능하게 됩니다. 즉, ‘birthplace’ 라는 단어를 word2vec은 birthplace 그 자체로만 생각한다면, FastText는 birth + place로 나눠서 생각할 수 있게 된다는 것입니다. 이는
- 모르는 단어(OOV, Out Of Vocabulary)에 대한 대응을 쉽게 하며
- 빈도가 적은 단어, 혹은 오타 등에 word2vec에 비해 강한 모습을 보여줍니다.
Uploaded by N2T
